When it comes to forecasting sales, most marketers rely on a simple function in excel, sometimes their boss’s fancy or even wild conjectures. While realistic forecasts are hard to put together, marketers can leverage pre-built machine learning regression models to their use. This now only gives realistic and pretty accurate predictions about your sales and can be adjusted for future shocks as well.
One of the most popular time series models in machine learning is the SARIMAX model. The SARIMAX (Seasonal Auto-Regressive Integrated Moving Average with eXogenous factor) model takes into account the seasonality of data to forecast time series data.
Since most of our sales data is seasonal, it’s one of the best models to apply to forecast your sales. One of the assumptions of the models is that the data needs to be stationary. Stationarity means that the mean, variance and autocorrelation structure do not change over time.
Just a statistics refresher, autocorrelation is a mathematical representation of the degree of similarity between a given time series and a lagged version of itself over successive time intervals.
While the data is rarely stationary in a real-world scenario, we can difference our time series data by deducting lagged values from the original series to make it stationary.
To check if the data is stationary or not, we use the ad fuller method. This method takes into account the original dataset and gives a p-value to the null hypothesis that the data is nonstationary. So if you have the p-value from the ad-fuller method to be less than 0.05 (generally accepted p-value), we can reject the null hypothesis that the data is non-stationary, meaning that the data is indeed stationary.
Once you have the differenced dataset, we need to plot the pacf and acf graphs to understand the order of the model. The order basically tells us which model to use, whether it is going to be Moving Average or Auto-Regressive or both integrated (ARIMA). One quick rule here;
Identification of an AR (Auto-regressive) model is often best done with the PACF.
For an AR model, the theoretical PACF “shuts off” past the order of the model. The phrase “shuts off” means that in theory the partial autocorrelations are equal to 0 beyond that point. Put another way, the number of non-zero partial autocorrelations gives the order of the AR model. By the “order of the model” we mean the most extreme lag of x that is used as a predictor.
Identification of an MA model is often best done with the ACF rather than the PACF.
For an MA model, the theoretical PACF does not shut off, but instead tapers toward 0 in some manner. A clearer pattern for an MA model is in the ACF. The ACF will have non-zero autocorrelations only at lags involved in the model. p,d,q p AR model lags d differencing q MA lags
What is “PACF” and “ACF”?
ACF gives us values of auto-correlation of any series with its lagged values. In simple terms, it describes how well the present value of the series is related to its past values. A time series can have components like a trend, seasonality, cyclic and residual. ACF considers all these components while finding correlations hence it’s a ‘complete auto-correlation plot’.
These are pre-built plots that come with stats model. Just import these and we have an ACF plot.
PACF is a partial autocorrelation function. Basically, it finds a correlation of the residuals (which remains after removing the effects which are already explained by the earlier lag(s)) with the next lag value hence ‘partial’ and not ‘complete’ as we remove already found variations before we find the next correlation. So if there is any hidden information in the residual that can be modeled by the next lag, we might get a good correlation and we will keep that next lag as a feature while modeling. Remember while modeling we don’t want to keep too many features that are correlated as that can create multicollinearity issues. Hence we need to retain only the relevant features.
Cutting through the complexities
Though this might sound too technical, there is a shortcut to all these steps which is called auto-arima. We first need to import pmd auto-arima and just provide the period for seasonality i.e. how many periods are there between 2 cycles. Eg: If your business has a peak season in a month, the cycle will be of 12 months. This will go as a parameter “m” in the pmd arima function. If you are not sure of the cycle length for your business, you can just plot the ACF graph and the period length between the spikes will tell you the cycle length. In the graph below the cycle, length is 12 as the spikes happen after 12, 24,36…. periods.
Other parameters include “d” which is the order of differencing for the non-seasonal data while “D” is the order of differencing for the seasonal data. You can set stepwise to “true” to enable auto-arima to take shortcuts to arrive at the best model. Finally, you set the “information criteria” either “aic” or “bic” to select the best model and run auto-arima to give you the best model.
In our case the best model is SARIMAX(1,1,0)(0,1,1,12). Simplifying the numbers in the bracket, (1,1,0) means that for the non-seasonal part of the data, it uses an Auto-regressive model (indicative from the first 1) without Moving Average (indicative from the last 0) with 1 order of differencing (indicative from middle 1).
The second brackets (0,1,1,12) tells us that for the seasonal part of the data it doesn’t use any Auto-regressive model (indicative from the first 0), with a Moving Average (indicative from the 1 at the third place) with one order of differencing (indicative from 1 at the second place) and seasonality of 12 periods (indicative from 12 at the last).
Note: in the case of pmd arima, we don’t need to difference the data as we are providing the order of differencing in the model itself. Once the model is fit, we can use it to predict future data by creating some offset dates. Plotting the final figures on the original data looks like
The orange line shows the predicted data while the blue line shows the original dataset. Here you can easily see how the predicted figures follow the same pattern as in the original dataset.
Note: you should split your original dataset into train and test splits to test your model before you use it in production.
You can similarly build a continuous model or run the model after later periods of time to adjust this to future shocks and trends. As and when the model has more data to learn from, it becomes better at predicting the future.
I have hosted the raw files to the dataset and the python code on my GitHub at https://github.com/AnkitBagga31/Timeseries_SARIMAX. Feel free to download it and just store your time-series sales data on your desktop by the name sales.csv (in case of mac) and run the python file in collab/jupyter and it should spit out the predicted sales for you.
It was the morning after I posted a giveaway on Linkedin for marketing spreadsheet utilities I had developed while I was running my own agency. What I saw the next day was something I hadn’t expected at all. 2500+ comments 700+ Likes and 300+ connection requests The technique was simple, get people to comment in […]
While machine learning and artificial intelligence are making news every now and then, it hasn’t changed the way we do marketing. Most marketers rely on the pre-built models in tools to guide their way through machine learning. While there are challenges in terms of learning python and implementing a lot of the machine learning models […]
If you are working in a niche market, search networks on AdWords and bing are bound to give you the most relevant traffic on your website. Here you have control over what search terms to target and optimize for long-tail keywords that have higher conversion rates. This scenario might sound like an SEO problem but […]
The World Wide Web has evolved multi folds over the last decade and to sell online is no longer just about having a website. With over 1.5 billion websites, businesses have little evolved to capture that attention and sell their products the way it works. Everything starts with a sales funnel. I am not going […]
Be it your assignment in your job application or a client pitch for your agency, if there is one thing people ask for is a Digital Marketing Plan. I am not going to bother you with free templates to design your plan, instead what I am going to focus on is the way to think […]
When it comes to multi-channel attribution models, the 2 most common models are Markov and Shapley models. While there are plenty of blogs talking about these models along with the Python libraries to implement them, it was a struggle to find resources that talk about these models, not to a data scientist but a marketer. […]
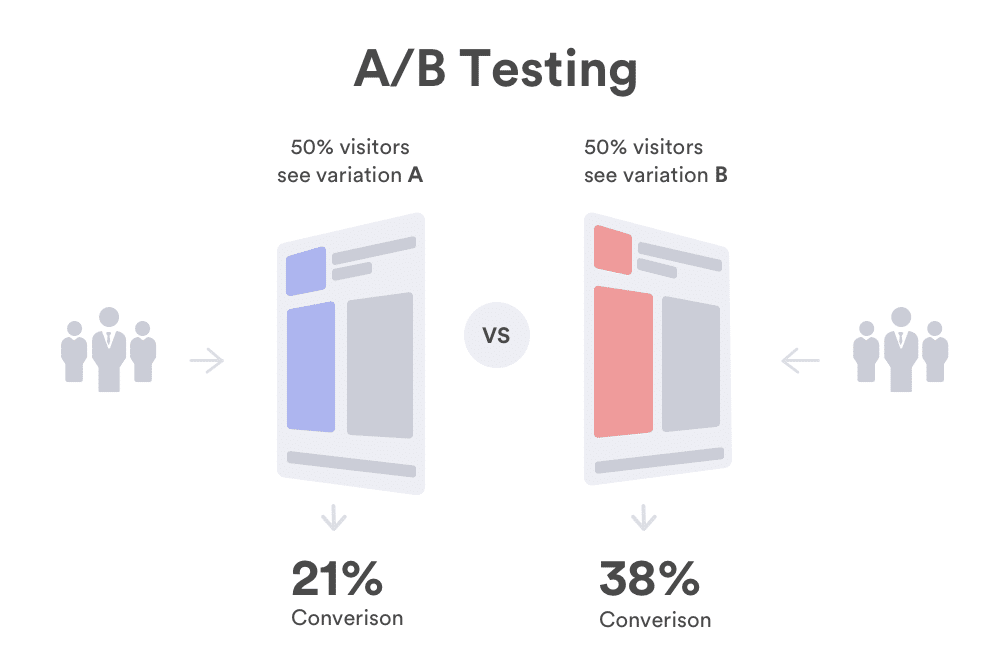
Marketing is science, an iterative process that involves testing and one of the common practices in testing is the A/B test. But unfortunately, over 90% of AB tests that are conducted, are done with the right intention but the wrong method. Typically this has got to do with Type1 and Type 2 errors with Type1 […]
After reading this research article, you would definitely doubt the effectiveness of the most popular social media platform and yes you guessed it right, it’s Facebook. With its most legitimate revenue coming from ads-based revenue but have you ever pondered over the authenticity of the entire model? While one could easily increase its reach on […]
Since the dawn of the internet age and the invention of the popular mailing service HotMail, one of the most profitable and of course misused marketing channels is email. If you are a marketer living in India you are fortunate enough to have the most relaxed rules when it comes to email marketing. Refer to […]
In 2019, global email users amounted to 3.9 billion users (Statista, 2020). This figure is set to grow to 4.3 billion users in 2023. That’s half of the world’s population. With such a ubiquitous channel for communication, companies rely heavily on email marketing to grow sales in the pursuit of cheaper conversions. But off late email marketing […]